It will not come as news to anyone streaming music via Spotify, Apple Music, Amazon, Tidal, etc – the playlist is the proprietary bit. The music is identical but your curated playlists are a barrier to moving.
I’m in love with this “Halloween” playlist because it isn’t cheesy songs like the Monster Mash and Ghostbusters, instead, it’s an adults’ Halloweenish soundtrack featuring great moody music from bands like M83, the Cure, the National and more. This plays nonstop at my house from Labor Day through the end of October.
But I don’t use Spotify. Because of the subsidized hardware, we use Amazon to stream to a bunch of Echos connected to speakers.
The solution is a free web app called Tune My Music. It’s free, and Amazon lists it as an approved way to import playlists. It can go back and forth between a great number of services, but for me I just setup a new Spotify account (yay hide my email!), granted access to TMM, and then playlist access to Amazon music, and it copied it over. Only one track was missing; good enough.
So maybe a bookmark in case you want to move between services.
So close! What’s she’s describing is status. Rank in the community, real or perceived. Will Storr wrote an excellent book about it, “The Status Game” that I highly recommend. (My local library had it.)
The MJ story is excellent and well worth your time. The Storr book is longer; this review might help you decide if you’d find it worthwhile.
The purpose of this post is to share two hard problems (in the CS sense of the term) that I and a friend solved with an LLM.
The problem and impetus
I’m friends with a couple of guys who have a podcast. (I know, right?) It’s been going for seven years or more now, is information-packed and more than once I’ve wanted to be able to search for something previously mentioned. Then, via Simon Willison I think, I learned about the amazing Whisper.cpp project that can run OpenAI’s Whisper speech-to-text model at high speed on desktop hardware. As others have said, “speed is a feature” and being able to do an hour of audio in a few minutes on a MacBookPro or Mini made the project interesting and feasible.
The project and goals
The overall goal of the project was to generate transcripts of every episode, index them with a local search engine, and serve the results as a static website. Open source code, no plan to monetize or commercialize, purely for the fun of it.
The code uses Python for logic, Makefiles for orchestration, wget for web downloads, mkdocs for website generation, xmltodict for the RSS parsing, Tenacity for LLM retries and rsync to deploy code. Nothing too exciting so far.
This let us generate a decent website. However, it was quickly obvious that Whisper would not suffice, since it doesn’t indicate who is speaking, a feature known as ‘diarization.’ After sharing the work on the TGN Slack, a member offered his employers’ product as a potential improvement. WhisperX, hosted on OctoAI, includes diarization. So instead of this wall of text
So now we have roughly an hours’ worth of audio, as JSON, with labels as to speaker. But the labels are not the names of the speakers. ‘SPEAKER_00‘ isn’t helpful. We need the names.
We need to somehow process 50-100KB of text, with all of the peculiarities of English, and extract from it the names of the speakers. Normally it’s the same two guys, but sometimes they do call-in type episodes with as many as 20 callers.
This is super hard to do with programming. I tried some crude “look for their usual intros” logic but it only worked maybe half of the time, and I didn’t want to deep-dive into NLP and parsing. At my day job, I was working on LLM-related things so it made sense to try one, but our podcasts were too large for the ChatGPT models available. Then came Claude, with 200k token windows and we could send the entire episode in a single go.
The code simply asks Claude to figure out who’s speaking. Here is the prompt:
The following is a public podcast transcript. Please write a two paragraph synopsis in a <synopsis> tag and a JSON dictionary mapping speakers to their labels inside an <attribution> tag. For example, {"SPEAKER_00": "Jason Heaton", "SPEAKER_01": "James"}. If you can't determine speaker, put "Unknown". If for any reason an answer risks reproduction of copyrighted material, explain why.
We get back the JSON dictionary, and the Python code uses that to build correct web pages. That works! Since we were paying maybe a nickel per episode, we also ask for a synopsis, another super hard programming task that LLMs can do easily. The results look like this:
Note the synopsis and the speaker labels.
LLMs are not just hype
It works great! We now have a website, with search index, that is decent looking and a usable reference. There’s more to do and work continues, but I’m super pleased and still impressed at how easy an LLM made two intractable problems. It’s not all hype; there are real, useful things you can do and I encourage you to experiment.
Lastly, please check out the website and enjoy. A complete time capsule of the podcast. I wonder if Archive.org needs a tool like this?
Big thanks to PyCharm and JetBrains for the FOSS license for the project. PyCharm is my favorite IDE, and the Pro version has things like usable CSV plugins plus I added a GitHub Copilot subscription as well.
Big thanks to OctoAI for the donated GPU hours while we worked out the bugs with their WhisperX hosting. (To be clear, once those were fixed I now pay as a normal customer.)
Notes and caveats
This uses Claude 3.5 ‘Sonnet’, their mid-tier model. The smaller model didn’t do as well, and the top-tier cost roughly 10x as much for similar results.
An hour of podcast audio converted to text is about 45k to 150k tokens. No problem at all for our 200k limit.
Anthropic has a billing system that appears designed to defend against stolen credit cards and drive-by fraud. I had to pay a reasonable $40 and wait a week before I could do more than a few requests. For two podcasts, it took about a week to process ~600 episodes. Even at the $40 level, I hit the 2.5M limit in under a hundred episodes.
About one episode in ten gets flagged as a copyright violation. Which they are not. Super weird. Even more weird is that making the same call again with no delay usually fixes the error. A Tenacity one-liner suffices. As you can see, we tried to solve this in the prompt but it seems to make no difference.
A friend is dealing with a large bureaucracy and it brought to mind this aphorism. It’s way too damned difficult to get a human on the phone any more and it’s not just cost.
214. Someone’s deceleration to exit, read a sign or rubberneck starts a little chain of responses that becomes a five-mile backup. So much of what turns out to be the huge evil of systems is the amplification of tiny reluctances to let go of a habit, to lift a phone, to look up and meet someone’s eyes.
-James Richardson, ‘Vectors: Aphorisms and Ten-Second Essays.’
Nearly perfect but just too fragile, leading to lots of orders:
They are nearly ideal. Zero flavor retention, easy to clean, great for hot coffee and ice cold beer and tea and sparkling water. I get the 18oz version in two packs. Plus they insulate well so no condensation and I can savor.
But they break so damned easily. Which is why I’ve repurchased so many times.
A while ago the Wirecutter recommended a glass lined bottle from Purist and I bought one. It’s as promised but the shape is too deep to hand wash and the lid is impossible to clean internally. so off I went.
And yes I firmly believe that coffee flavor is best from a wide opening shape and glass or ceramic. Reddit agrees… mostly.
The main features I want are insulation, glass or ceramic lining and large at 16oz or so. Two full cups from my French press. I found this Asobu:
It’s… excellent. Super slick coating, insulated well, a breeze to clean, coffee tastes great. Nice and wide so the aromas are good.
The shape is a lot like my Yeti that I still have.
I’ve had it a few days, rigorously testing with coffee, tea, sparkling water, beer, mint tea and it’s great. Super slick ceramic, nice cork, wide and stable, good value at $30. Worthy of my YouShouldBuy category!
Sometimes you buy a watch because it’s just right. Proportions, dimensions, luminosity, legibility, price, movement, style. This one preoccupied me for a couple of months and arrived last week.
Really enjoying wearing it.
Downsides so far – the lumed numerals blur in the dark into blobs, so the initial legibility decreases a bit. I miss having a date available. Since it has unidirectional winding, there’s noticeable rotor spin that you can feel and hear.
Overall strong positive. At 36 by 10.8, it’s super comfortable. I love the design and style. Legibility is excellent as is timekeeping. At 1100 with bracelet (always buy the bracelet!) the value is good for a Swiss made watch this well detailed and finished.
There’s a larger 38mm version, but for me, with the all-dial case, 36 is perfectly sized.
Farer page is here. No relationship, just a happy customer.
A friend of mine did an interesting bit of research and data gathering that I’ve not seen elsewhere and I thought I’d share here.
If you read about energy and markets, you might have read about EROEI: Energy return on energy invested. E.g: It might take 20 gallons of oil to extract a 55g barrel of oil.
So what’s the energy cost to refine a gallon of gasoline?
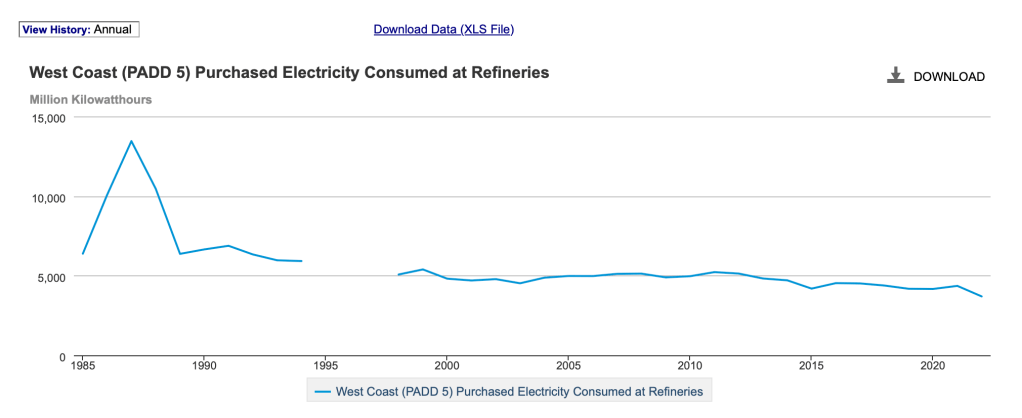
To get an answer, my friend found the government page showing the energy used by “Petroleum Administrative for Defense District 5. Basically, west-coast refineries.”. It’s here. A snapshot graph:
If you do the math (to tip my hat to a scientist I admire), the result is 8.6kWh/gallon. To get that number, you
take the annual electricity purchased by the refinery (X)
Calculate the proportion of gasoline vs total refined output (Y) (19.45 gallons gas per 44.77 gallons refined output)
Divide X/Y
That’s more than I would have guessed. Our 2018 Chevrolet Bolt EV holds about 60kWh and can drive around 180 miles, by way of comparison. So the refining energy could power an average EV sedan 34 miles. Which is higher than the average EPA mileage of a comparable ICE sedan.
Food for thought. As my friend put it, “charging an EV will always require less energy than an equivalent gasoline powered vehicle, and would always be cheaper for the end user if not for subsidies to the petroleum industry.”
If you run your own self-hosted WordPress and would like to, you know, blog now on it, you too may have gotten the maddening error “Unable to read the WordPress site on that URL”
This, though their help page does not tell you, is a filthy lie. Do the following whilst cursing their late-stage-capitalist bastard hearts:
Append “/xmlrpc.php” to the URL. That’s all that it takes.
So example.com becomes example.com/xmlrpc.php
Of course, this is only broken on self-hosted sites. Bastards, like I said.